Tag Processing
Why is Tag Processing Essential?
One of the most important things in setting up a localization process, is content processing. This is the stage where users should define:
- How exactly to handle different types of content.
- Which information to include into localization and what to skip.
- How to process specific tags.
This is an important stage as the file structure might be quite complicated when the complexity of website increases. Setting up content processing correctly will enable you to avoid extra translation expenses and get a much more efficient and clear localization process. The "Tags" tab in a channel settings will allow you to setup tag processing rules.
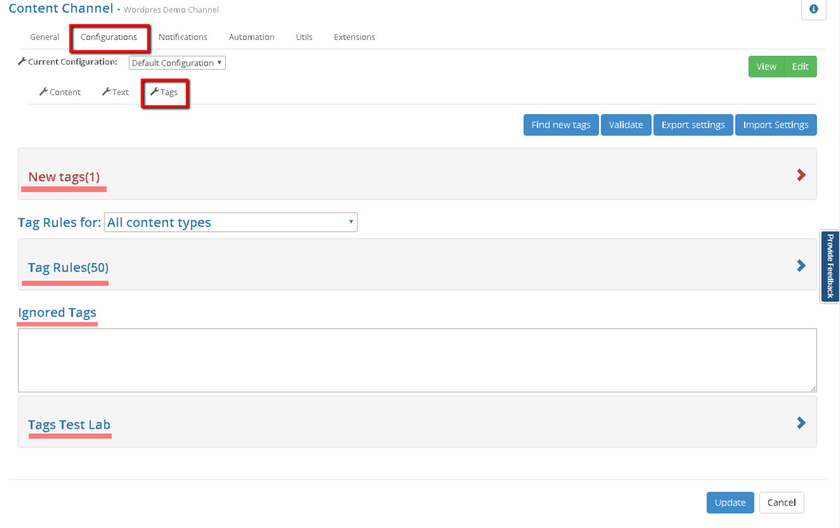
On this form you will find following sections:
- New Tags - this section represents a list of tags, you do not have processing rules for.
- Tag Rules - represents a list of tag processing rules.
- Ignored Tags - represents a list of tags which are ignored in a localization process.
- Tags Test Lab - allows you to run rule applying in a test mode, on a specific piece of content.
New Tags
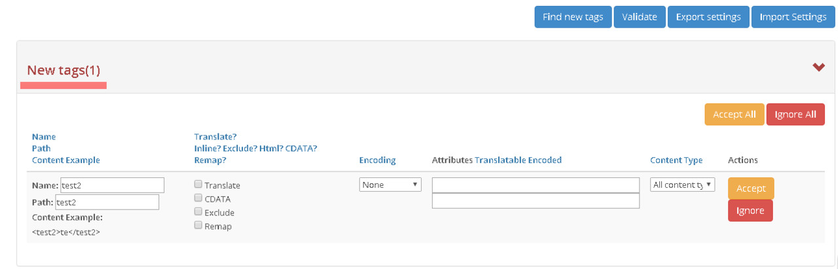
Whenever a content passes through the content channel and tags with no processing rules are found (new tags), the iLangl system alerts you and shows these tags in the "New Tags" section.
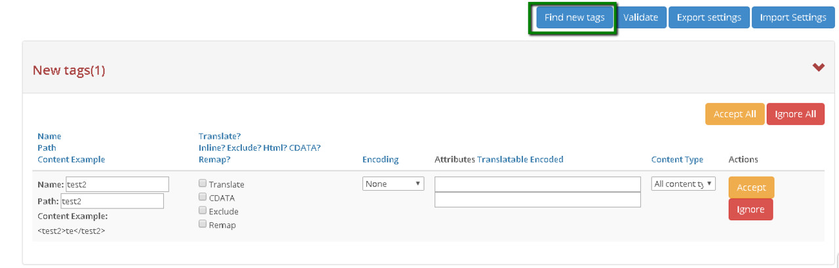
 To find new tags that have been added with new content type:
To find new tags that have been added with new content type:
Select the content type to look for new tag.
Now click on ‘Find new tags’. The system will find all available new tags for this specific website.
3. Select the primary language from the ‘Select Language’ drop down menu. Once selection is done, click ‘OK’
4. You can now select specific content types for which the new tags should be displayed. You can also select all content types to check for new tags.
5. Now system analyses, finds all new tags and displays it. Here we can decide (pre-processing) what we should include in translation and what to exclude.
Apply tag rules under the tag tab.
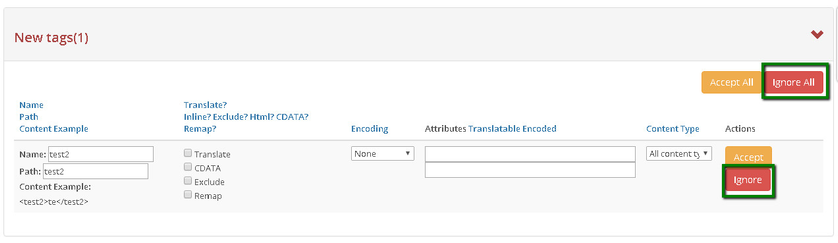
Working with New Tags
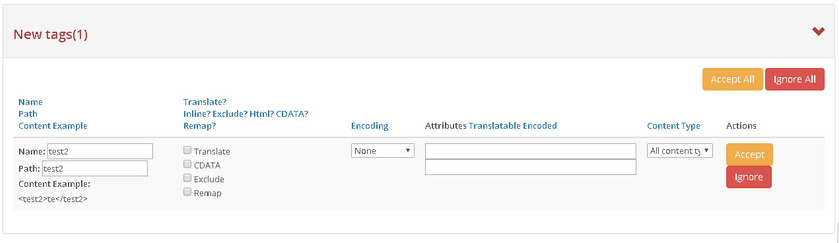
- The New Tag display page allows you to define how to handle tags found. You can perform the following functions with new tags:
Ignore the tag - If the content of this tag is not something that has to be translated or somehow used you can direct the system to ignore this tag. To ignore a tag click the "Ignore" button against the relevant row.
Accept the tag - If a tag's content is something that you want to process, you can add a new processing rule for this tag. This is done by filling in the rule attributes and clicking the "Accept" button.
You can also apply accept or ignore rule action to all the new tags found via the "Accept All" and "Ignore All" buttons respectively.
Accept or Ignore New Tags
2. After tags are accepted or ignored, users can add/edit and overview tag processing rules for different types of content. Users can pre-process content under the new tags.
Here users can decide what should be included in translation and what should be excluded.
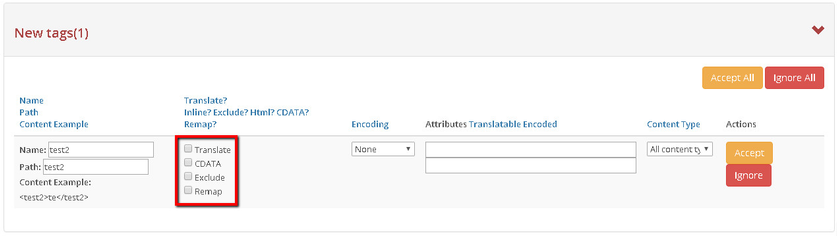
By placing a check mark near the respective options users can process the tags in these ways:
Translate - This flag defines whether the tag content should be translated.
CDATA - Allows to wrap a content of a tag into a CDATA
Exclude - This flag defines whether the tag content should be excluded from translation. The main advantage of this option is, even if a tag is excluded from translation, users can choose to keep the field. It does not affect target content.
3. Once translation type is chosen users can decide the encoding rule to be used. Users can choose from JSON, HTML, or PHP.
4. In the Translatable Attributes field users can define a set of specific tag attributes that should be translated.
5. In the Content Type field define the content type on which the translation rule is to be applied.
The wide combination of these rules offered by iLangl give you numerous possibilities when it comes to content processing. For example: you can check in the "CDATA" and "Html" flags. This will mean that
a tag's content will be wrapped into a CDATA and treated as an HTML. In case you have a situation, where a content of a same tag (and even path) has to be translated in one case, but skipped in another,
depending on a content of another tag, you can define a tag and a path, and specify a condition. This will mean that a rule will be applied only for a tag in a specific path when specific conditions are met.
Setting up Custom Tag Rules
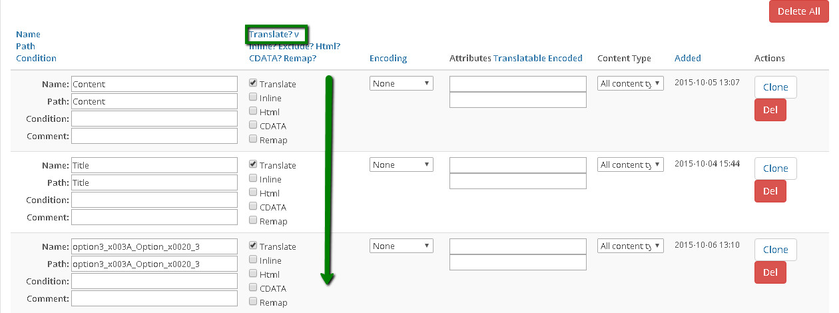
In this section users can add or edit and overview the tag processing rules for different types of content:
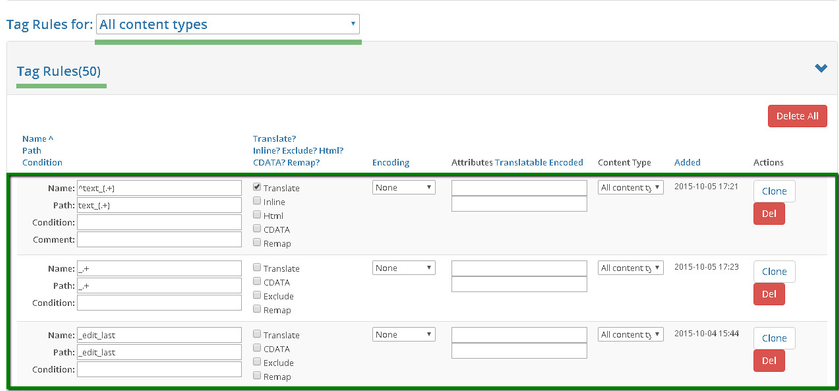
To view the tag rules, select the content type, you want to overview rules for. In this example we have 103 Tag processing rules set, which are going to be applied to all the content types.
Tag rules are defined via the following set of attributes:
- Name Path - this is a name of a tag, combined with a specific path, if necessary;
- Condition - condition can define a specific case when a tag rule has to be applied to a tag, see more details in tag conditions language article;
- Translate? Inline? Exclude? Html? CDATA? - a set of the following attributes:
- Translate - this flag defines whether a content of a tag should be translated or not;
- Inline - defines whether a tag should be considered as an inline or an outline one;
- Exclude - defines whether a tag should be excluded from a content;
- Html - states that a content of a tag should be processed as HTML. Feature supported by Memsource for XML files;
- CDATA - allows to wrap a content of a tag into a CDATA;
- Encoding - defines an encoding, this rule is going to use. Encodings are defined in the "Text" tab of your content channel's settings;
- Translatable attributes - defines a set of tag's attributes which have to be translated;
- Content Type - defines a content type, rule is going to be applied to;
- Added - this is a rule's creation date\time;
A combination the above set of rules gives users a broad range of possibilities in content processing, for example:
- You can check in the "CDATA" and "Html" flags, this will mean that a tag's content will be wrapped into a CDATA and treated as an HTML.
- In case you have a situation, where a content of a same tag (and even path) has to be translated in one case, but skipped in another, depending on a content of another tag.
In cases like this you can define a tag and a path, and specify a condition. This will mean that a rule will be applied only for a tag in a specific path when conditions are met.
The following actions can be performed under the 'Tag Rules' section:
- Clone - adds a new tag rule, with cloned attributes;
- Del - deletes a tag rule;
- Delete All - deletes all tag rules for a currently selected content type;
You can also order data in this section by a specific column or an attribute by clicking on the attribute name (Translate / Inline/ Exclude / HTML / CDATA).
Ignored Tags
This section represents a list of tags, or regular expressions which define what tags your connector is going to ignore. This means that when a tag from this list is found in the content, it will not be processed or translated. To ignore tags check the “Exclude” option against the tag rule. Tags in this section are separated by ',’ (Figure ).
Note: Ignored tags will not be deleted.

In this example system will ignore the occurrence of tags: "_accessoires_0_naam" and "_accessoires". In order to add a new tag to the list of ignored, you can either type it manually, or click the "Ignore" button in the list of new tags and it will be automatically added to the list of ignored:
It is also possible to define tags to ignore via regular expressions. For example, you can ignore all tags by typing in the ".+" expression.
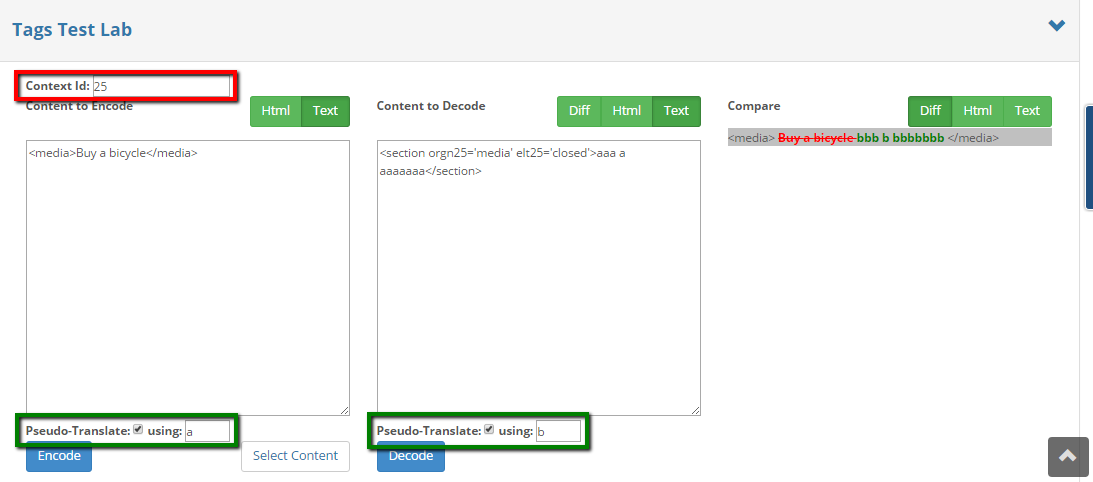
Tags Test Lab
The tags test lab allows you to test your tag processing rules on a specific piece of content. Users can copy and paste the test text here, or open a real source content,
to make sure everything is processed as expected, before making the website go live. The general test lab's behavior is described here. The tags test lab has few additional features:
Context Id - Allows to emulate a content id, in order to make sure it is not broken during the processing.
Pseudo-Translate - Gives ability to run a pseudo-translation, to get an overview of what is going to be translated.
This method of manual filtering of fields that need to be translated gives users control over translation. Even simple websites have more than 100 properties. The content field properties increase tremendously
when the complexity of the website increases. So it becomes difficult to manually choose what fields to translate. To overcome this issue make use of iLangl’s unique feature Text Tag Rules as described above.